Parquet vs. Arrow
- Parquet : Disk에 저장할 목적의 columnar format
- 주로 Storage에 파일형태로 저장
- I/O reduction에 Priority
- Projection pushdown : Column pruning
- Filter pushdown : statistics 기반의 Filtering
- 대부분 Streaming형태의 Access
- Arrow : In-memory용 columnar format
- 주로 하나의 Query를 처리하는데 사용되는 format
- CPU throughput에 Priority
- Streaming Access + Random Access
Parquet File Layout
-
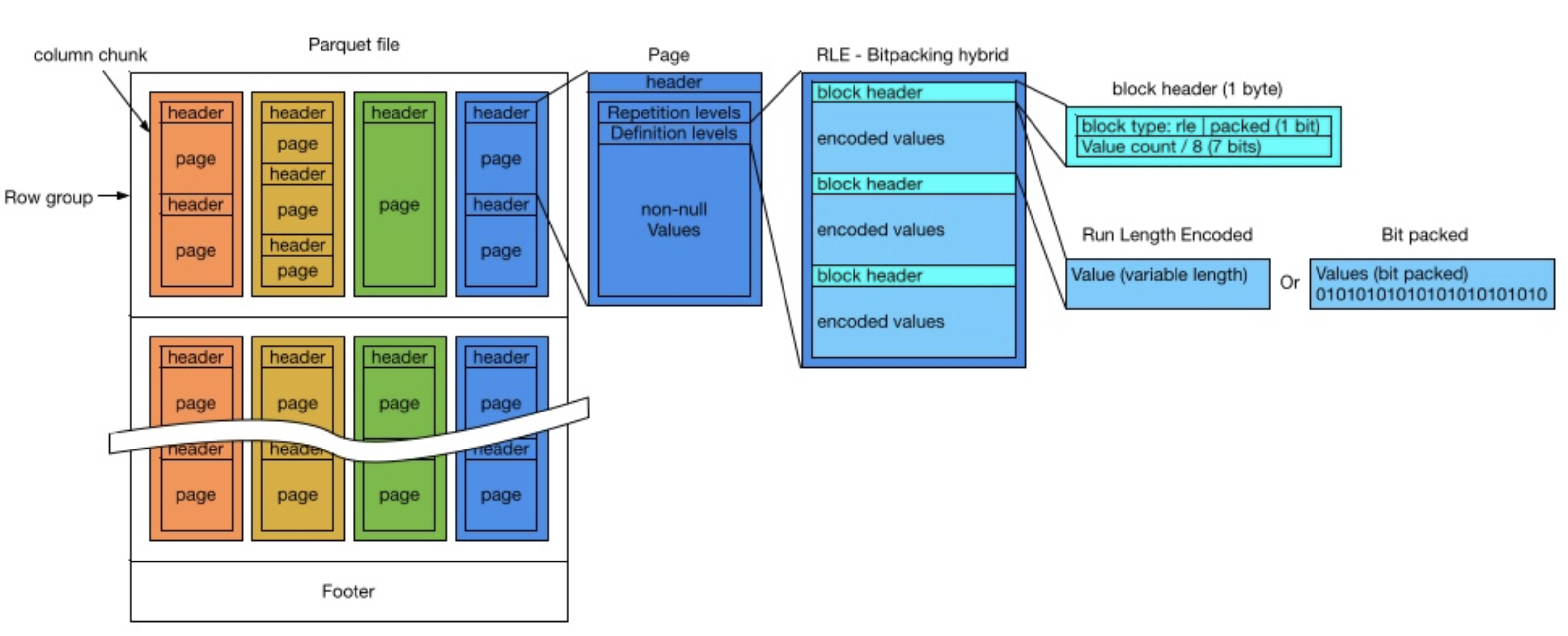
Hierarchy : Row group > Column chunk > Page > Header + Data (Repetition & Definition Level, non-null values)
- 병렬화 단위 (Unit of parallelization)
- MapReduce - File/Row Group
- IO - Column chunk
- Encoding/Compression - Page
-
파일 구조
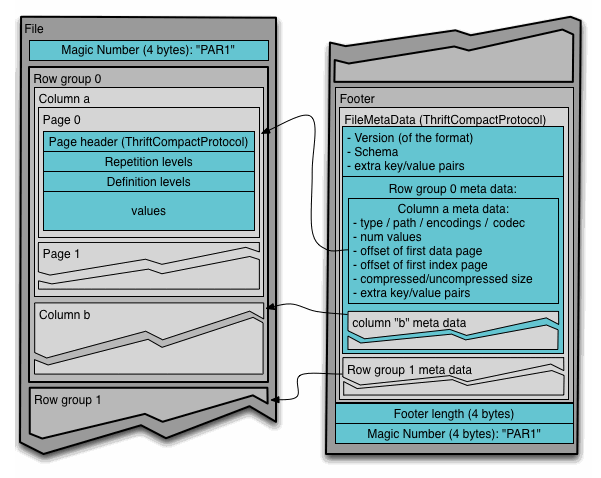
- Footer : FileMetaData
- Schema, Version
- Row groups Metadata : Column Chunk location
- Row group
- Horizontal Partitioning of data into rows
- Columns Chunks
- 연속된 Page들로 구성됨
- Page
- 가장 작은 저장 단위
- Repetition levels data : List, Set 같은 자료형을 지원하기 위한 데이터
- Definition levels data : column value 각각의 null, non null 값을 표시
- Encoded values : non-null column values을 encoding한 데이터
- Compression/ Encoding 단위 → Page별로 다른 Encoding Type을 쓸 수 있다
- Supported Encoding : https://github.com/apache/parquet-format/blob/master/Encodings.md
- Plain Encoding
- Dictionary Encoding
- The dictionary will be stored in a dictionary page per column chunk.
- Dictionary page + Data Page
- If the dictionary grows too big, whether in size or number of distinct values, the encoding will fall back to the plain encoding.
- Dictionary page format: the entries in the dictionary - in dictionary order - using the plain encoding.
- Data page format: the bit width used to encode the entry ids stored as 1 byte (max bit width = 32), followed by the values encoded using RLE/Bit-Packing Hybrid. (with the given bit width).
- The dictionary will be stored in a dictionary page per column chunk.
- Run Length Encoding / Bit-Packing Hybrid
1 2 3 4 5 6
rle-bit-packed-hybrid: <length> <encoded-data> length := length of the <encoded-data> in bytes stored as 4 bytes little endian (unsigned int32) encoded-data := <run>* run := <bit-packed-run> | <rle-run> bit-packed-run := <bit-packed-header> <bit-packed-values> rle-run := <rle-header> <repeated-value> - The bit-packing
1 2 3 4 5 6
dec value: 0 1 2 3 4 5 6 7 bit value: 000 001 010 011 100 101 110 111 bit label: ABC DEF GHI JKL MNO PQR STU VWX bit value: 10001000 11000110 11111010 bit label: HIDEFABC RMNOJKLG VWXSTUPQ- bit-packed-run-len and rle-run-len must be in the range [1, 2^31 - 1]. This means that a Parquet implementation can always store the run length in a signed 32-bit integer.
- etc : Delta Encoding (INT32, INT64), Delta Length Byte Array(Byte Array), Delta String(Byte Array), Byte Stream Split(Float, Double)
- Source Code : https://github.com/apache/parquet-mr/tree/master/parquet-column/src/main/java/org/apache/parquet/column/values
- 가장 작은 저장 단위
- Recommended Configuration
- Row group size : 512MB - 1GB (larger sequential IO)
- Data page size : 8KB
Parquet Schema
- Parquet stores nested data structures in a flat columnar format : Dremel paper from Google
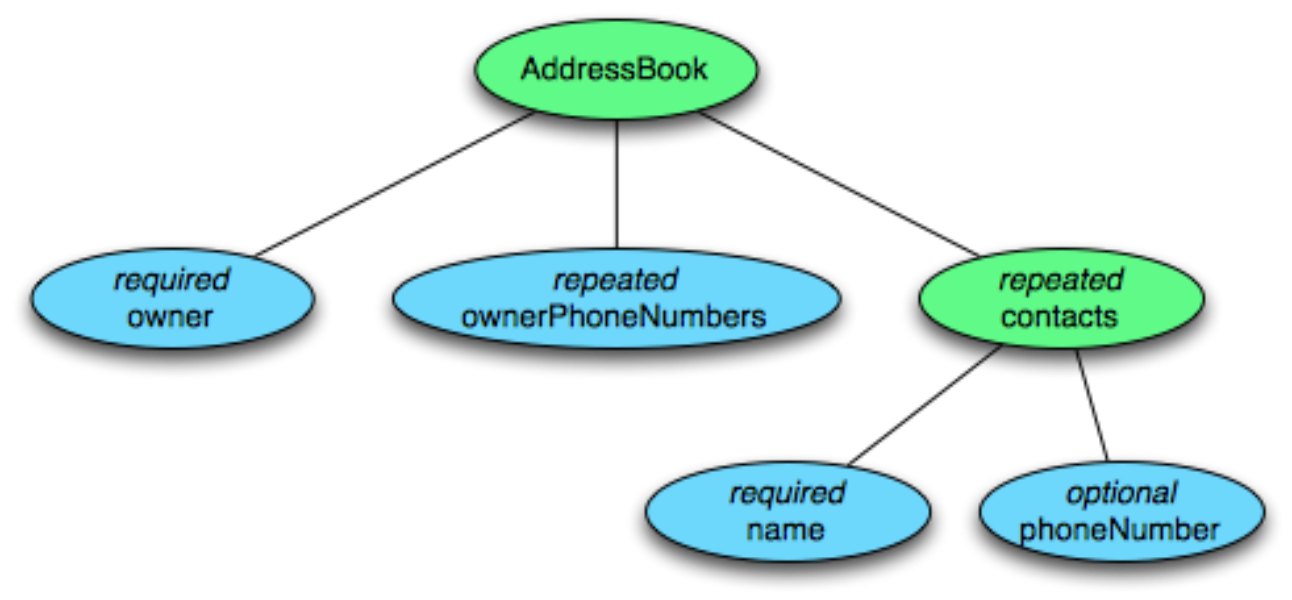
- Schema : describes data structures, Similar to “Protocol buffer(protobuf)”
- group fields : Nesting
- repeated fields : Repetition, List나 Set을 표현
- required, optional : nullable을 표현
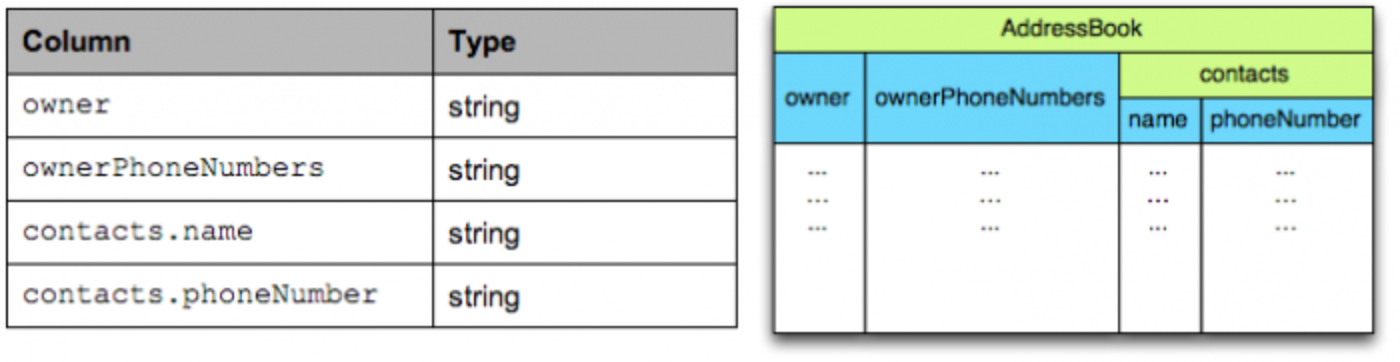
1 2 3 4 5 6 7 8
message AddressBook { required string owner; repeated string ownerPhoneNumbers; repeated group contacts { required string name; optional string phoneNumber; } }
- Definition levels
- Nested schema : field가 처음 null이되는 level을 저장 (from root (0 level) to maximum level of the column)
1 2 3 4 5 6 7
message ExampleDefinitionLevel { optional group a { optional group b { optional string c; } } }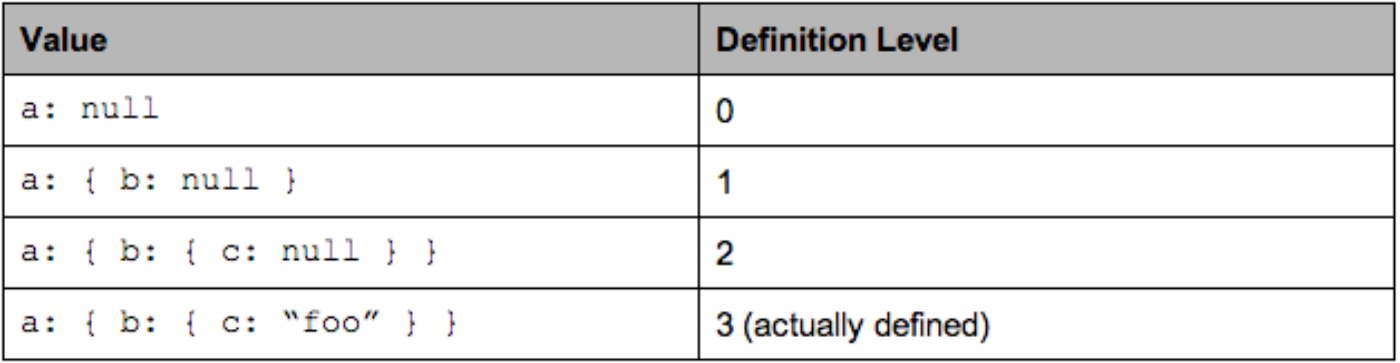
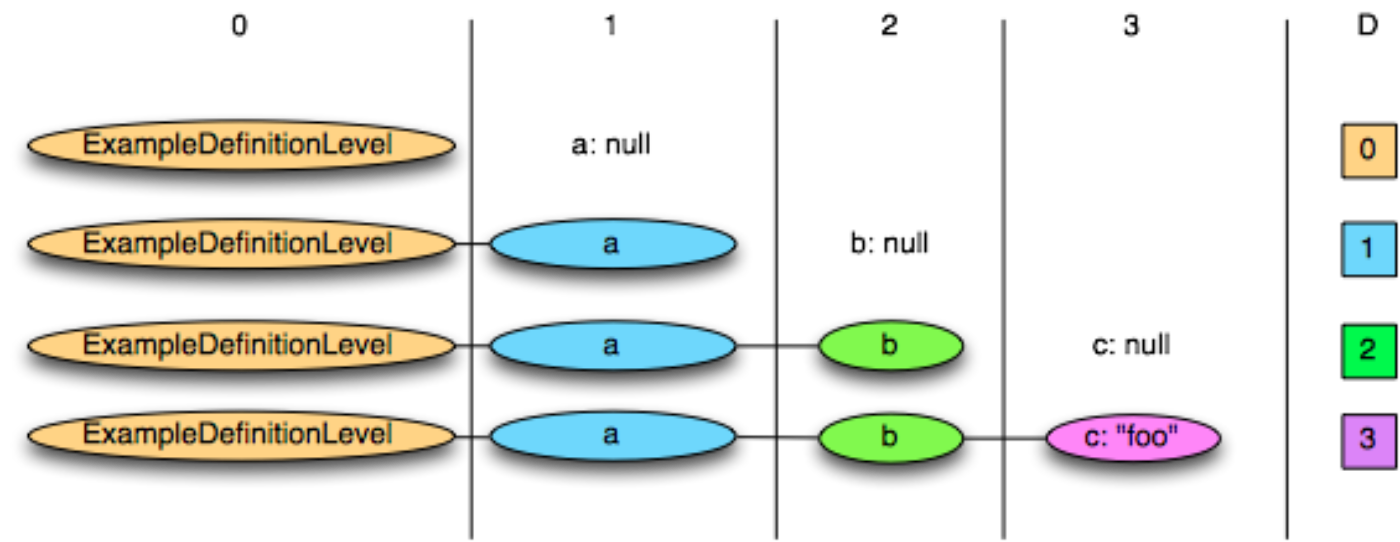
- Flat schema : Optional field를 null여부에 따라 0, 1 bit로 encoding
- Nested schema : field가 처음 null이되는 level을 저장 (from root (0 level) to maximum level of the column)
- Repetition levels
- 새로운 List가 시작할 때 저장되는 값
- 어느 Level에서 새로운 List를 생성해야 하는 지 Marking하는 정보
1 2 3 4 5
message nestedLists { repeated group level1 { repeated string level2; } }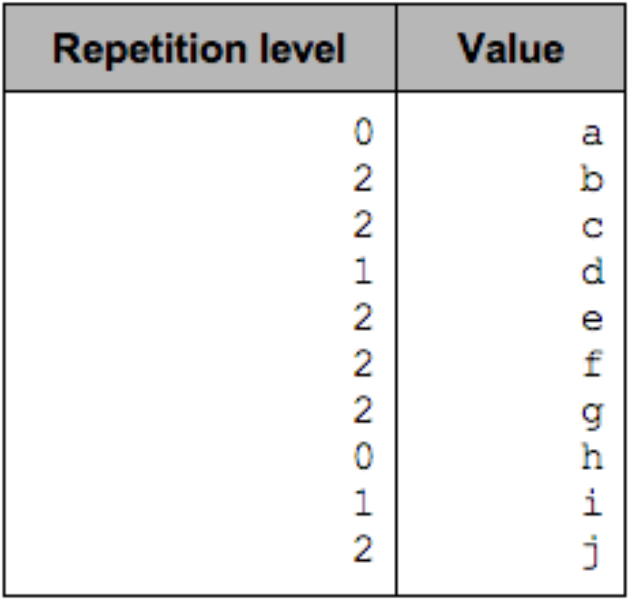
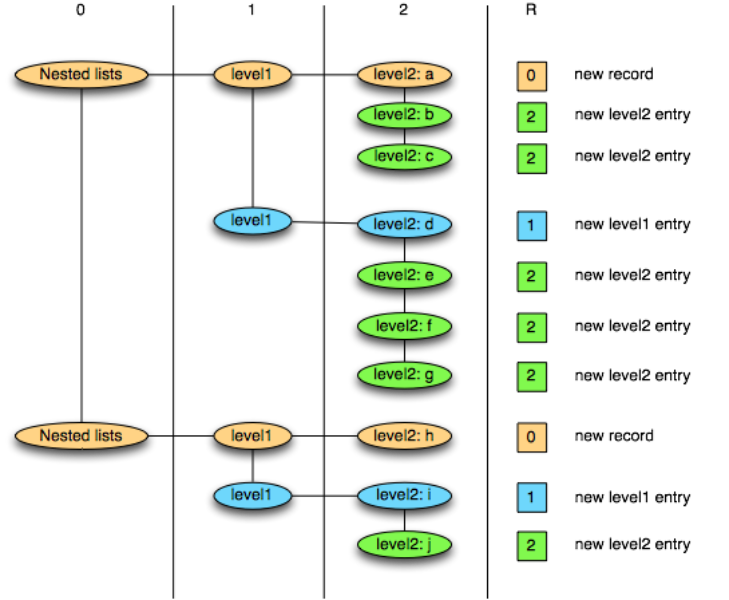
- Flat schema with all fields required : the repetition levels and definition levels are omitted completely
Parquet Predicate Pushdown
- Page의 Header에는 Statics정보가 Optional하게 들어가 있고 Predicate Pushdown 후 Filter에 부합하지 않는 Page들을 걸러내는 용도로 사용함
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
/** Data page header */ struct DataPageHeader { /** Number of values, including NULLs, in this data page. **/ 1: required i32 num_values /** Encoding used for this data page **/ 2: required Encoding encoding /** Encoding used for definition levels **/ 3: required Encoding definition_level_encoding; /** Encoding used for repetition levels **/ 4: required Encoding repetition_level_encoding; /** Optional statistics for the data in this page**/ 5: optional Statistics statistics; } /** * Statistics per row group and per page * All fields are optional. */ struct Statistics { /** * DEPRECATED: min and max value of the column. Use min_value and max_value. * * Values are encoded using PLAIN encoding, except that variable-length byte * arrays do not include a length prefix. * * These fields encode min and max values determined by signed comparison * only. New files should use the correct order for a column's logical type * and store the values in the min_value and max_value fields. * * To support older readers, these may be set when the column order is * signed. */ 1: optional binary max; 2: optional binary min; /** count of null value in the column */ 3: optional i64 null_count; /** count of distinct values occurring */ 4: optional i64 distinct_count; /** * Min and max values for the column, determined by its ColumnOrder. * * Values are encoded using PLAIN encoding, except that variable-length byte * arrays do not include a length prefix. */ 5: optional binary max_value; 6: optional binary min_value; } -
Statics정보를 활용하지 않은 Naive한 구현
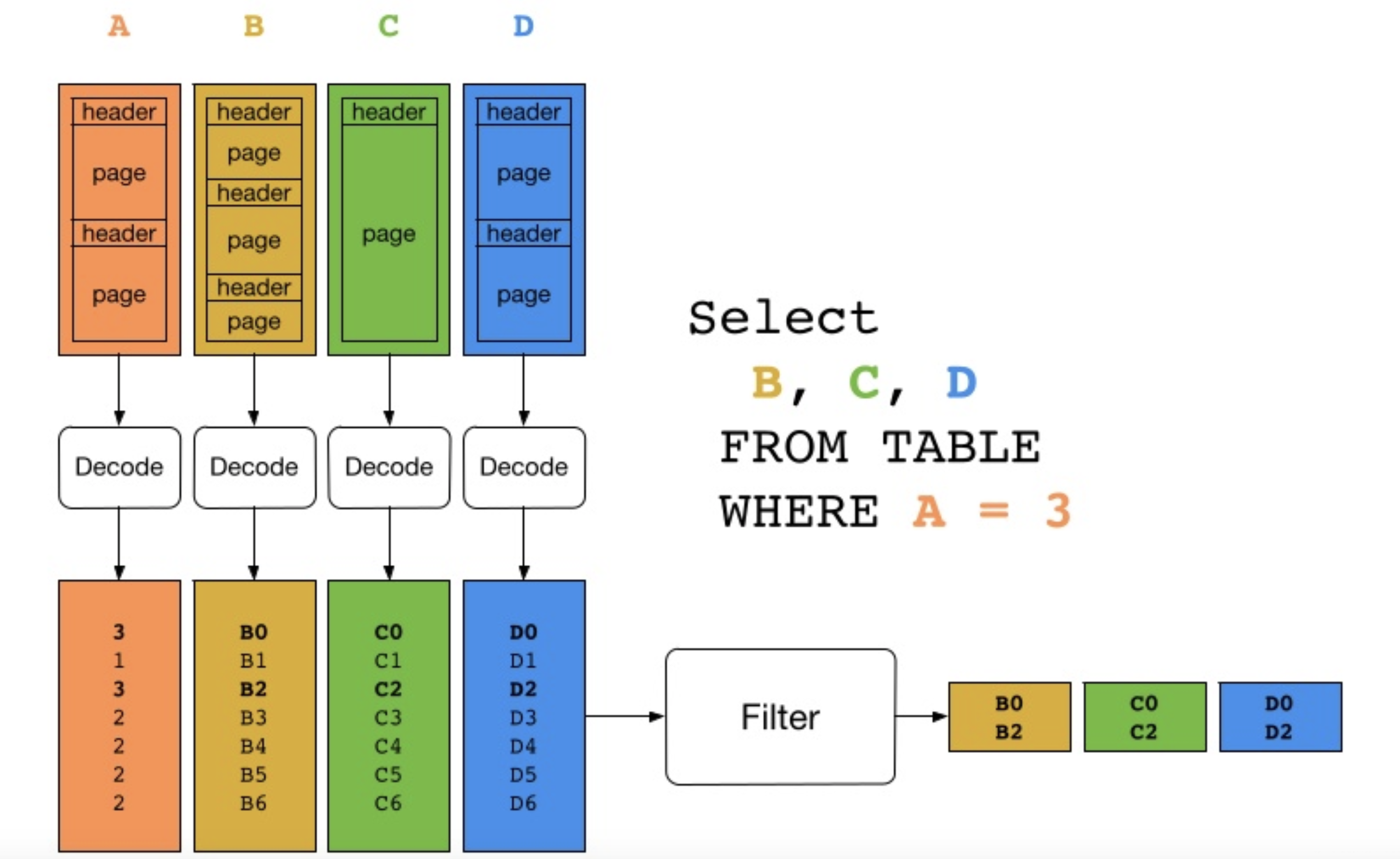
-
Statics정보를 활용한 최적화
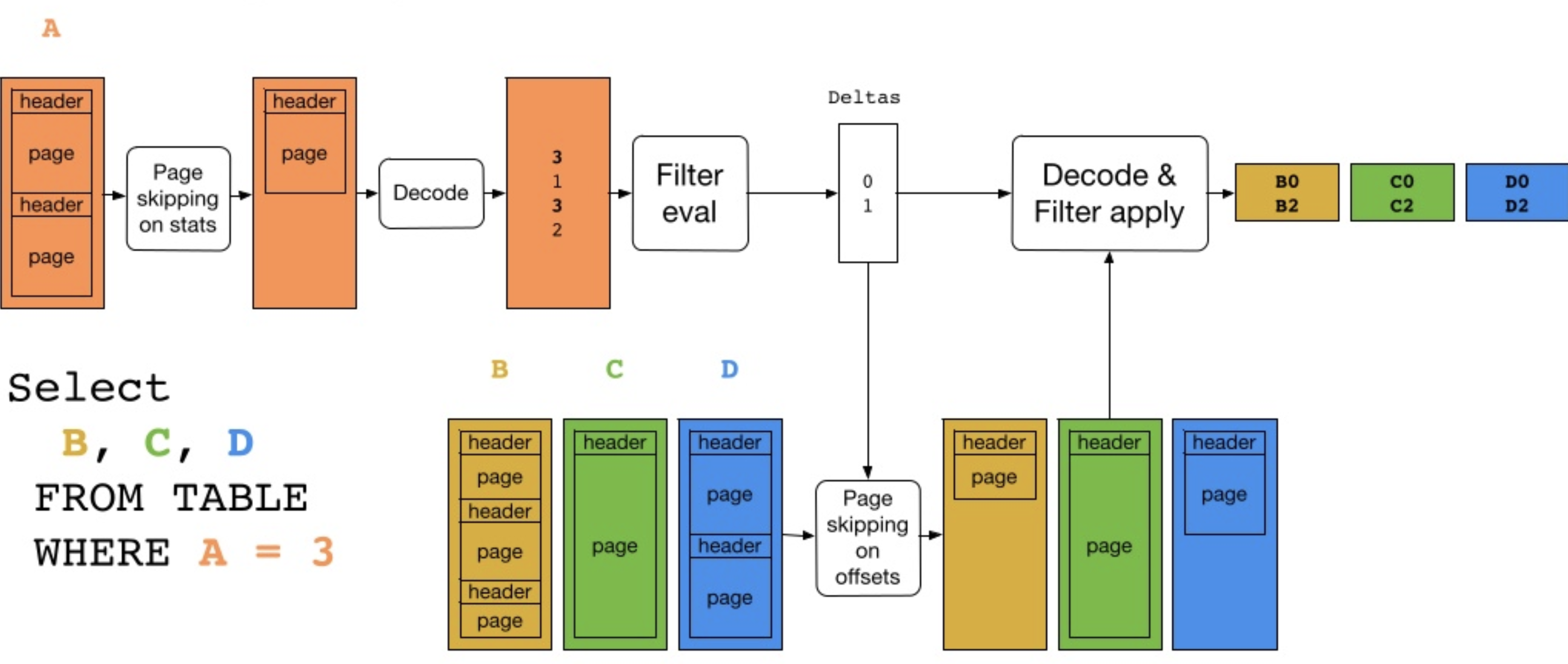
(1) Filter Column의 Column Chunk load
(2) Page 별 MIN, MAX Stat 기반으로 Decoding할 Page 선택
(3) Values를 decoding한 후 Filtering으로 Delta vector 도출 (Skipping할 Index)
(4) Column 별 Page Offset Range가 다르므로(Data Size기준으로 Page를 분할하기 때문), B,C,D Column Chunk는 (2)에서 선택된 Delta Vector의 Index와 겹치는 Page들만 Decoding
(5) (3)의 Delta Vector를 B,C,D Page에도 적용해 Filtering
Speeding Up SELECT Query with Page Indexes
- 질의에 사용되는 Column의 Data를 다른 형태로 적재 후 성능 비교
- SORTED: generated random data and then sorted the whole data.
- CLUSTERED_n: generated random data, split it into n-buckets and then sorted each bucket separately. This simulates partially sorted data that occurs in real-life workloads. For example, data sets comprised of timestamps of events.
- RANDOM: We generated random data and did not apply any sorting.
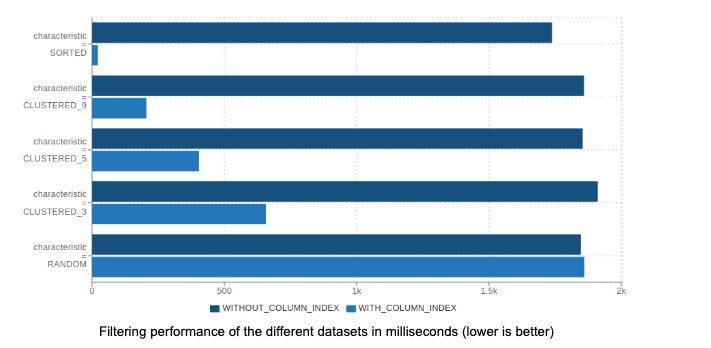
- Page Size 조절
- parquet.page.size
- parquet.page.row.count.limit : 중복이 많은 Column의 경우 Encoding 후 Data Size가 작아서 전체 Data가 한 Page에 들어갈 수 있으므로 page의 row count 제한도 걸 수 있음
References
- https://github.com/apache/parquet-format
- https://github.com/apache/parquet-format/blob/master/Encodings.md
- https://blog.twitter.com/engineering/en_us/a/2013/dremel-made-simple-with-parquet.html
- https://www.dremio.com/webinars/columnar-roadmap-apache-parquet-and-arrow/
- https://www.slideshare.net/Hadoop_Summit/the-columnar-roadmap-apache-parquet-and-apache-arrow-102997214
- https://blog.cloudera.com/speeding-up-select-queries-with-parquet-page-indexes/