Apache Arrow의 목적 및 장점
- Cross language간 호환되는 memory format → No overhead for cross-system communication
- 여러 Project가 동일한 기능을 Share할 수 있다.(ex) Parquet-to-Arrow reader
- modern CPU에 맞게 디자인된 memory format : maximize CPU throughput
- Ecosystem : Parquet, Spark, Dask, Data Preview, Dremio, Fletcher, GeoMesa, GOAI, Omnisci, MATLAB, pandas 등등
Arrow Columnar Format의 특징
- Sequential access(scan)를 위한 Data의 인접성
- O(1) (constant-time) random access
- SIMD and vectorization-friendly : Allocate memory on aligned addresses (multiple of 8- or 64-bytes) and pad (overallocate) to a length that is a multiple of 8 or 64 bytes.
- Elements in numeric arrays will be guaranteed to be retrieved via aligned access.
- On some architectures alignment can help limit partially used cache lines.
- SIMD register width와 matching 시키기 위해서 64 bytes alignment 권장
- Relocatable without “pointer swizzling”, allowing for true zero-copy access in shared memory (Pointer swizzling : Pointer를 disk에 쓰기 전에 Reload할 수 있게 Object ID로 전환해서 저장하는 것)
Google FlatBuffers
- Apache Arrow는 Cross Lanaguage 간 호환되는 memory format을 지원하기 위해 내부적으로 FlatBuffers 를 사용합니다.
- FlatBuffers : Cross platform serialization library for C++, C#, C, Go, Java, JavaScript, Lobster, Lua, TypeScript, PHP, Python, and Rust.
- Parsing/Unpacking이 불필요 : Direct memory access
- 장점 : ProtoBuf와 유사하지만 FlatBuffers는 Object에 접근하기 전에 Deserialize하지 않아도 되기 때문에 ProtoBuf보다 성능이 뛰어나고 메모리 사용량이 적음
- 단점 : ProtoBuf보다 코드 생성량이 많음
- Tutorial : https://google.github.io/flatbuffers/flatbuffers_guide_tutorial.html
- FlatBuffers Schema : IDL file로 정의되고 flatc를 이용 C++, java 등 Source file로 compile된다. Application에서는 Source file을 import해 object를 memory block에서 읽어들이거나 object를 memory block에 쓸 수 있다.
- 지원되는 type : table(class object), struct, union, vector(denoted with [type]), enum, string, primitive types
- IDL의 root type : root table for the serialized data.
- Serialization (Object to Binary)
- FlatBufferBuilder 이용
- FlatBufferBuilder : Serialize된 Memory Buffer를 생성하는 Builder
- Table(class object) 생성 시 string,vector,table이 Table memory안에 nesting되는 게 아님 → 먼저 string,vector,table 등의 객체를 생성한 후 reference를 참조하는 구조
- FlatBufferBuilder Finish를 호출하면 Serialized buffer가 생성됨
- FlatBufferBuilder 이용
- Binary to Object : No deserialization
- Java : flatc 로 생성한 class에 “getRootAs + Class명” 함수 이용해서 메모리에 바로 접근
- C++ : flatc 로 생성한 class에 “Get + Class명” 함수 이용해서 메모리에 바로 접근
1 2 3 4 5 6 7 8 9 10
// Java byte[] bytes = /* the data you just read */ java.nio.ByteBuffer buf = java.nio.ByteBuffer.wrap(bytes); // Get an accessor to the root object inside the buffer. Monster monster = Monster.getRootAsMonster(buf); // C++ uint8_t *buffer_pointer = /* the data you just read */; // Get a pointer to the root object inside the buffer. auto monster = GetMonster(buffer_pointer);
FlatBuffers & Apache Arrow
- Arrow에 IPC protocol이나 File Structure는 결국 FlatBuffers Schema로 정의된다. https://github.com/apache/arrow/tree/master/format
Serialization and Interprocess Communication (IPC)
- Sender : Serializing Schema & Record Batches into a stream of binary payloads
- Receiver : Reconstructing Schema & Record Batches from these payloads without need for memory copying
- IPC Streaming Format
- Schema messages + Record Batch messages
- Schema에 Dictionary Encoding된 Column이 포함되어 있다면 해당 Column의 DictionaryBatch가 나온 후 Record Batch message가 옴
1 2 3 4 5 6 7 8 9 10 11 12
<SCHEMA> <DICTIONARY 0> ... <DICTIONARY k - 1> <RECORD BATCH 0> ... <DICTIONARY x DELTA> ... <DICTIONARY y DELTA> ... <RECORD BATCH n - 1> <EOS [optional]: 0xFFFFFFFF 0x00000000>
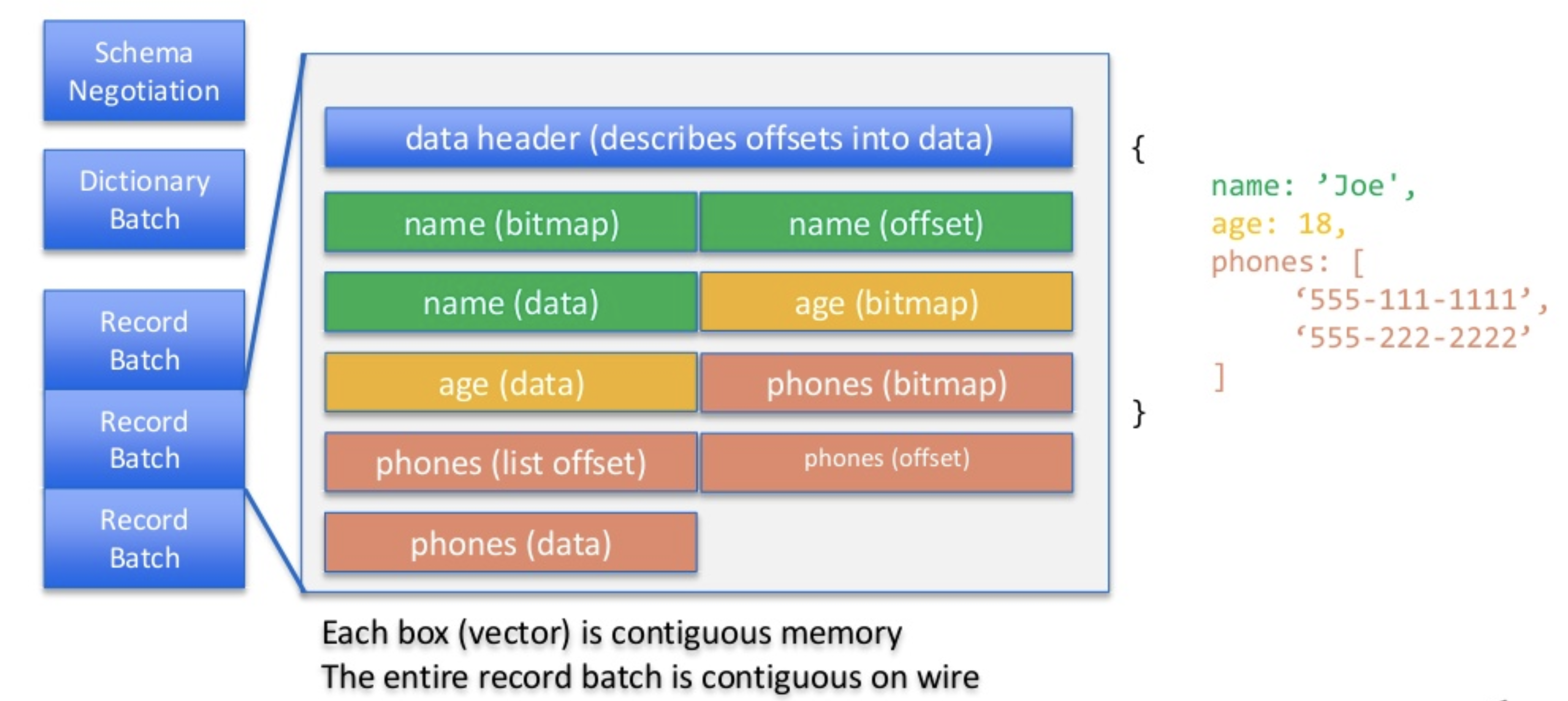
- File Format
- Body는 Streaming format과 동일
- Footer영역 : Schema 복사본 포함
1 2 3 4 5 6
<magic number "ARROW1"> <empty padding bytes [to 8 byte boundary]> <STREAMING FORMAT with EOS> <FOOTER> <FOOTER SIZE: int32> <magic number "ARROW1">
Messages
- Protocol of Message
1 2 3 4 5
<continuation: 0xFFFFFFFF> <metadata_size: int32> <metadata_flatbuffer: bytes> <padding> <message body>
- <metadata_flatbuffer>
- https://github.com/apache/arrow/blob/master/format/Message.fbs
- Message Version & Type
1 2 3 4 5 6 7 8 9 10
union MessageHeader { Schema, DictionaryBatch, RecordBatch, Tensor, SparseTensor } table Message { version: org.apache.arrow.flatbuf.MetadataVersion; header: MessageHeader; bodyLength: long; custom_metadata: [ KeyValue ]; }
- <padding>
- For 8-bytes alignment
- <message body>
- Schema, RecordBatch, DictionaryBatch의 Serialize된 FlatBuffers binary
- The complete serialized message must be a multiple of 8 bytes so that messages can be relocated between streams.
- <metadata_flatbuffer>
- Schema Message
- https://github.com/apache/arrow/blob/master/format/Schema.fbs
- Schema describes the columns in a row batch
- Filed의 Array로 구성됨
1 2 3 4 5 6
table Schema { endianness: Endianness=Little; fields: [ Field ]; // User-defined metadata custom_metadata: [ KeyValue ]; }
- Field : Name & Type of column in a record batch + children fields of a nested type.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
table Field { name: string; nullable: bool; type: Type; /// Present only if the field is dictionary encoded. dictionary: DictionaryEncoding; /// children apply only to nested data types like Struct, List and Union. children: [ Field ]; /// User-defined metadata custom_metadata: [ KeyValue ]; }
- Type
- Arrow에서 지원하는 Logical Data Type
- Type 각각에 고유한 Memory Layout이 정의되어 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
... table Int { bitWidth: int; // restricted to 8, 16, 32, and 64 in v1 is_signed: bool; } enum Precision:short {HALF, SINGLE, DOUBLE} table FloatingPoint { precision: Precision; } ... union Type { Null, Int, FloatingPoint, Binary, Utf8, Bool, Decimal, Date, Time, Timestamp, Interval, List, Struct_, Union, FixedSizeBinary, FixedSizeList, Map, Duration, LargeBinary, LargeUtf8, LargeList, }
- Filed의 Array로 구성됨
- RecordBatch Message
- Row들이 Columnar형식으로 serialize된 data
- RecordBatch Header
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
struct FieldNode { /// The number of value slots in the Arrow array at this level of a nested /// tree length: long; /// The number of observed nulls. null_count: long; } struct Buffer { /// The relative offset into the shared memory page where the bytes for this /// buffer starts offset: long; /// The absolute length (in bytes) of the memory buffer. length: long; } table RecordBatch { /// number of records / rows. The arrays in the batch should all have this /// length length: long; /// Nodes correspond to the pre-ordered flattened logical schema nodes: [FieldNode]; /// Buffers correspond to the pre-ordered flattened buffer tree buffers: [Buffer]; }
- FieldNode : 각각 field의 length 와 null count.
- Buffer : Message body의 Buffer의 memory offset과 length
- RecordBatch Body : end-to-end 8-byte로 align된 memory buffer의 sequence
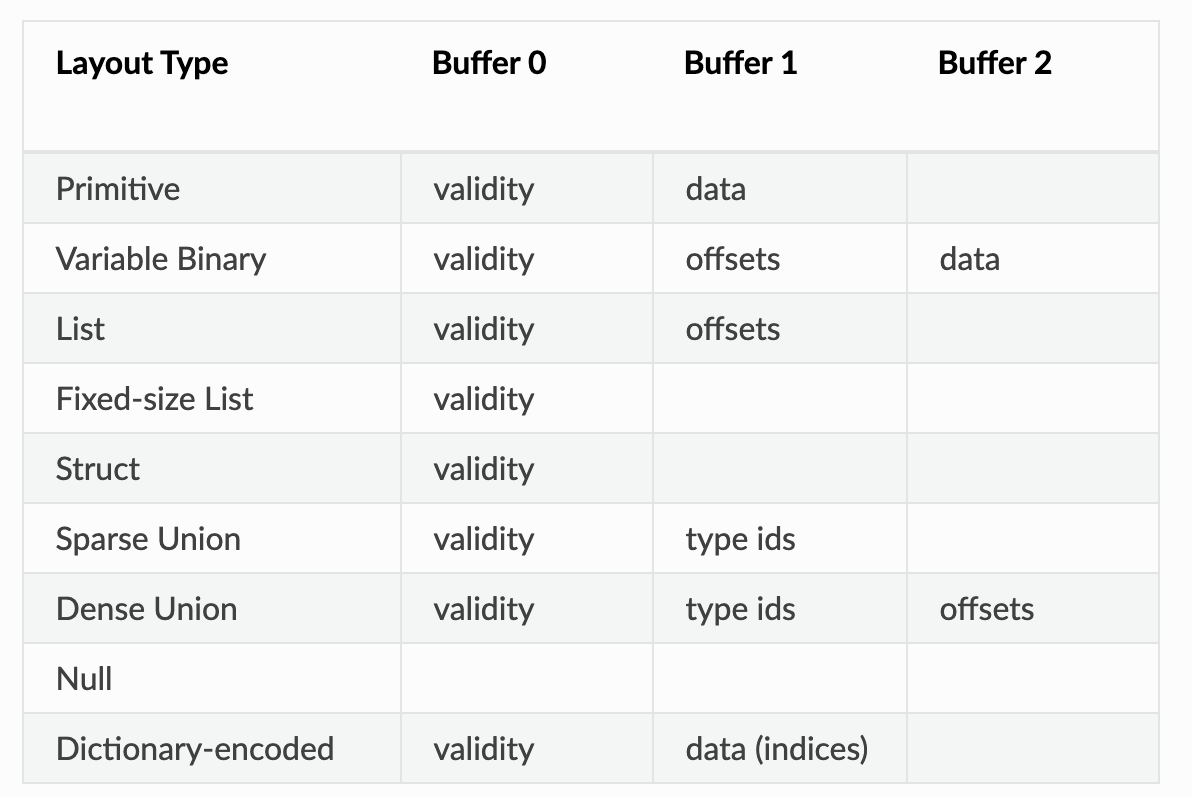
- Buffer의 Memory Layout : Column의 Logical Type에 따라서 결정됨
- Validity bitmaps
- null 여부를 bit로 marking하는 Buffer
- LSB numbering
1 2 3 4 5
values = [0, 1, null, 2, null, 3] bitmap j mod 8 7 6 5 4 3 2 1 0 0 0 1 0 1 0 1 1
- Validity bitmaps
- Layout Type
- https://arrow.apache.org/docs/format/Columnar.html#fixed-size-primitive-layout
- Fixed-size Primitive Layout : validity buffer + data buffer
- Example Layout
1 2
Int32 Array [1, null, 2, 4, 8]
- Length: 5, Null count: 1
-
Validity bitmap buffer
Byte 0 (validity bitmap) Bytes 1-63 00011101 0 (padding) -
Value Buffer
Bytes 0-3 Bytes 4-7 Bytes 8-11 Bytes 12-15 Bytes 16-19 Bytes 20-63 1 unspecified 2 4 8 unspecified
- Variable-size Binary Layout : validity buffer + offset buffer + data buffer
- 각각의 value가 0이상의 byte를 가짐
- Offset Buffer : offset을 저장 → (32bit or 64bit) x (array length + 1)
1 2
slot_position = offsets[j] slot_length = offsets[j + 1] - offsets[j] // (for 0 <= j < length)
- Nested Types (Struct, List) : data buffer가 없음
- Variable-size List Layout
- Fixed-Size List Layout
- Struct Layout
- Union Layout : Dense & Sparse Union
- Dictionary-encoded Layout
- The values are represented by an array of signed integers representing the index of the value in the dictionary.
- https://arrow.apache.org/docs/format/Columnar.html#dictionary-encoded-layout
- RecordBatch Message Body 예시
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
col1: Struct<a: Int32, b: List<item: Int64>, c: Float64> col2: Utf8 -> After flattened (pre-order traversal) FieldNode 0: Struct name='col1' FieldNode 1: Int32 name='a' FieldNode 2: List name='b' FieldNode 3: Int64 name='item' FieldNode 4: Float64 name='c' FieldNode 5: Utf8 name='col2' -> Buffers buffer 0: field 0 validity buffer 1: field 1 validity buffer 2: field 1 values buffer 3: field 2 validity buffer 4: field 2 offsets buffer 5: field 3 validity buffer 6: field 3 values buffer 7: field 4 validity buffer 8: field 4 values buffer 9: field 5 validity buffer 10: field 5 offsets buffer 11: field 5 data
- Dictionary Message https://arrow.apache.org/docs/format/Columnar.html#dictionary-messages
Java Implementation of Deserializing RecordBatch Message
- IPC나 File로 교환되는 Class Object
1
2
3
4
5
6
7
8
9
10
11
12
13
org.apache.arrow.flatbuf
// Generated Sources by flatc
// Message의 Header
public final class Message extends Table
// Message Body, 즉 RecordBatch의 Header
public final class RecordBatch extends Table
// RecordBatch Header에 포함됨. Column Array의 Meta정보(value count, null count)
public final class FieldNode extends Struct
// RecordBatch Header에 포함됨. Column Array의 binary 상 offset
public final class Buffer extends Struct
-
Messeage Deserialization
(1) Message Header를 deserialize & Message body의 binary를 ArrowBuf로 Wrapping
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
// org.apache.arrow.vector.ipc.message.MessageChannelReader public MessageResult readNext() throws IOException { // Read the flatbuf message and check for end-of-stream MessageMetadataResult result = MessageSerializer.readMessage(in); if (result == null) { return null; } Message message = result.getMessage(); ArrowBuf bodyBuffer = null; // Read message body data if defined in message if (result.messageHasBody()) { int bodyLength = (int) result.getMessageBodyLength(); bodyBuffer = MessageSerializer.readMessageBody(in, bodyLength, allocator); } return new MessageResult(message, bodyBuffer); } // org.apache.arrow.vector.ipc.message.MessageSerializer public static ArrowBuf readMessageBody(ReadChannel in, long bodyLength, BufferAllocator allocator) throws IOException { ArrowBuf bodyBuffer = allocator.buffer(bodyLength); if (in.readFully(bodyBuffer, bodyLength) != bodyLength) { throw new IOException("Unexpected end of input trying to read batch."); } return bodyBuffer; }
(2) Message Header가 RecordBatch인지 확인 후 Message Body binary를 RecordBatch로 Deserialize
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
// org.apache.arrow.vector.ipc.ArrowStreamReader public boolean loadNextBatch() throws IOException { prepareLoadNextBatch(); MessageResult result = messageReader.readNext(); // Reached EOS if (result == null) { return false; } if (result.getMessage().headerType() == MessageHeader.RecordBatch) { ArrowBuf bodyBuffer = result.getBodyBuffer(); // For zero-length batches, need an empty buffer to deserialize the batch if (bodyBuffer == null) { bodyBuffer = allocator.getEmpty(); } ArrowRecordBatch batch = MessageSerializer.deserializeRecordBatch(result.getMessage(), bodyBuffer); loadRecordBatch(batch); checkDictionaries(); return true; } else if (result.getMessage().headerType() == MessageHeader.DictionaryBatch) { // if it's dictionary message, read dictionary message out and continue to read unless get a batch or eos. ArrowDictionaryBatch dictionaryBatch = readDictionary(result); loadDictionary(dictionaryBatch); loadedDictionaryCount++; return loadNextBatch(); } else { throw new IOException("Expected RecordBatch or DictionaryBatch but header was " + result.getMessage().headerType()); } }
(3) Message Body에서 RecordBatch Header 생성 후 및 RecordBatch의 body를 Column별로 binary를 Slice한 후 ArrowRecordBatch object로 wrapping → 결국 ArrowRecordBatch object는 Column chunk binary List를 가지게 된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
// org.apache.arrow.vector.ipc.message.MessageSerializer public static ArrowRecordBatch deserializeRecordBatch(Message recordBatchMessage, ArrowBuf bodyBuffer) throws IOException { RecordBatch recordBatchFB = (RecordBatch) recordBatchMessage.header(new RecordBatch()); return deserializeRecordBatch(recordBatchFB, bodyBuffer); } public static ArrowRecordBatch deserializeRecordBatch(RecordBatch recordBatchFB, ArrowBuf body) throws IOException { // Now read the body int nodesLength = recordBatchFB.nodesLength(); List<ArrowFieldNode> nodes = new ArrayList<>(); for (int i = 0; i < nodesLength; ++i) { FieldNode node = recordBatchFB.nodes(i); if ((int) node.length() != node.length() || (int) node.nullCount() != node.nullCount()) { throw new IOException("Cannot currently deserialize record batches with " + "node length larger than INT_MAX records."); } nodes.add(new ArrowFieldNode(node.length(), node.nullCount())); } List<ArrowBuf> buffers = new ArrayList<>(); for (int i = 0; i < recordBatchFB.buffersLength(); ++i) { Buffer bufferFB = recordBatchFB.buffers(i); ArrowBuf vectorBuffer = body.slice(bufferFB.offset(), bufferFB.length()); buffers.add(vectorBuffer); } if ((int) recordBatchFB.length() != recordBatchFB.length()) { throw new IOException("Cannot currently deserialize record batches with more than INT_MAX records."); } ArrowRecordBatch arrowRecordBatch = new ArrowRecordBatch(checkedCastToInt(recordBatchFB.length()), nodes, buffers); body.getReferenceManager().release(); return arrowRecordBatch; }
Conversion Between Parquet & Arrow
- Representation of Flat schema
Arrow의 경우 Parquet과 달리 null value도 memory를 차지 함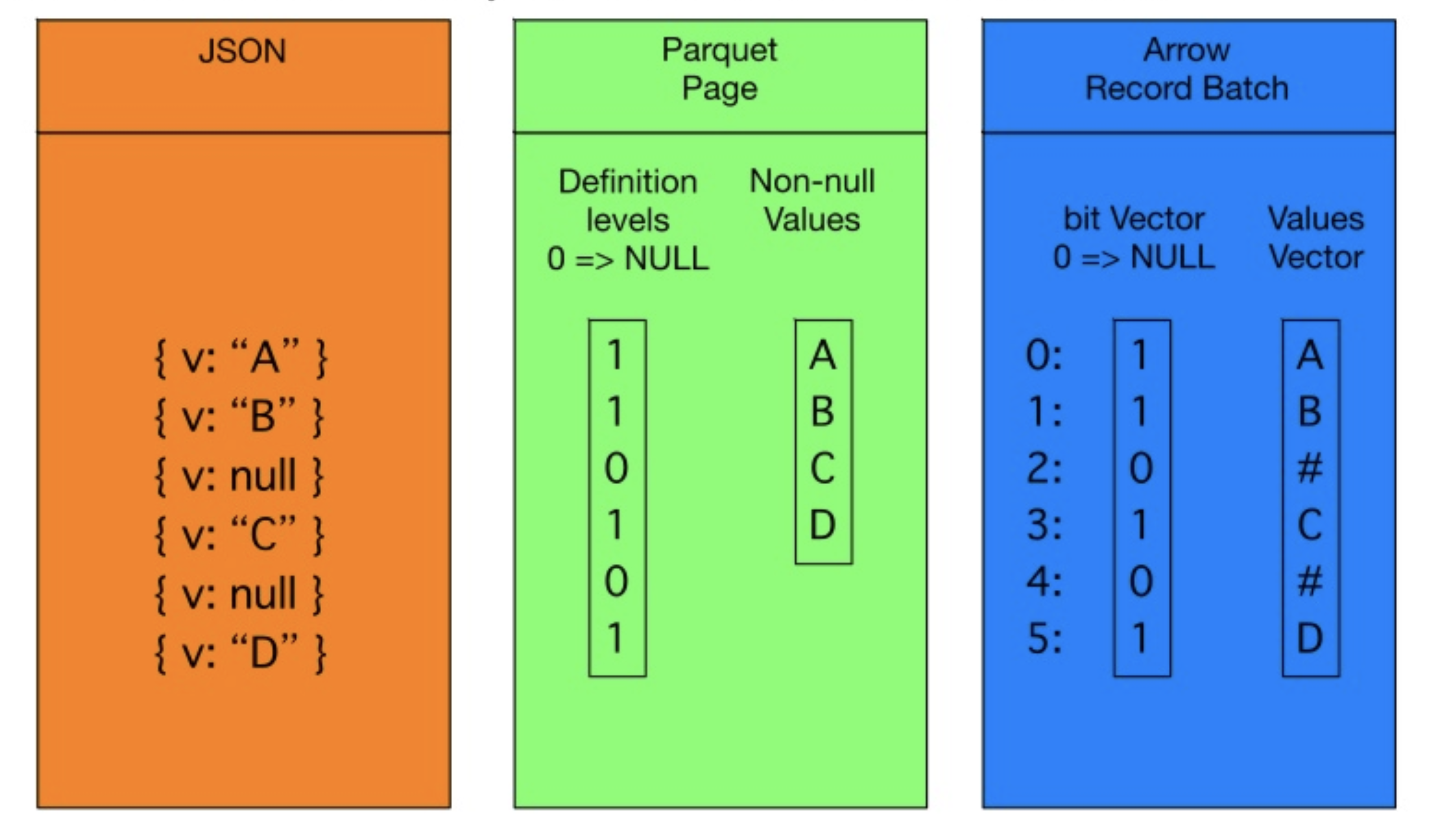
- Naive Conversion (Parquet → Arrow)
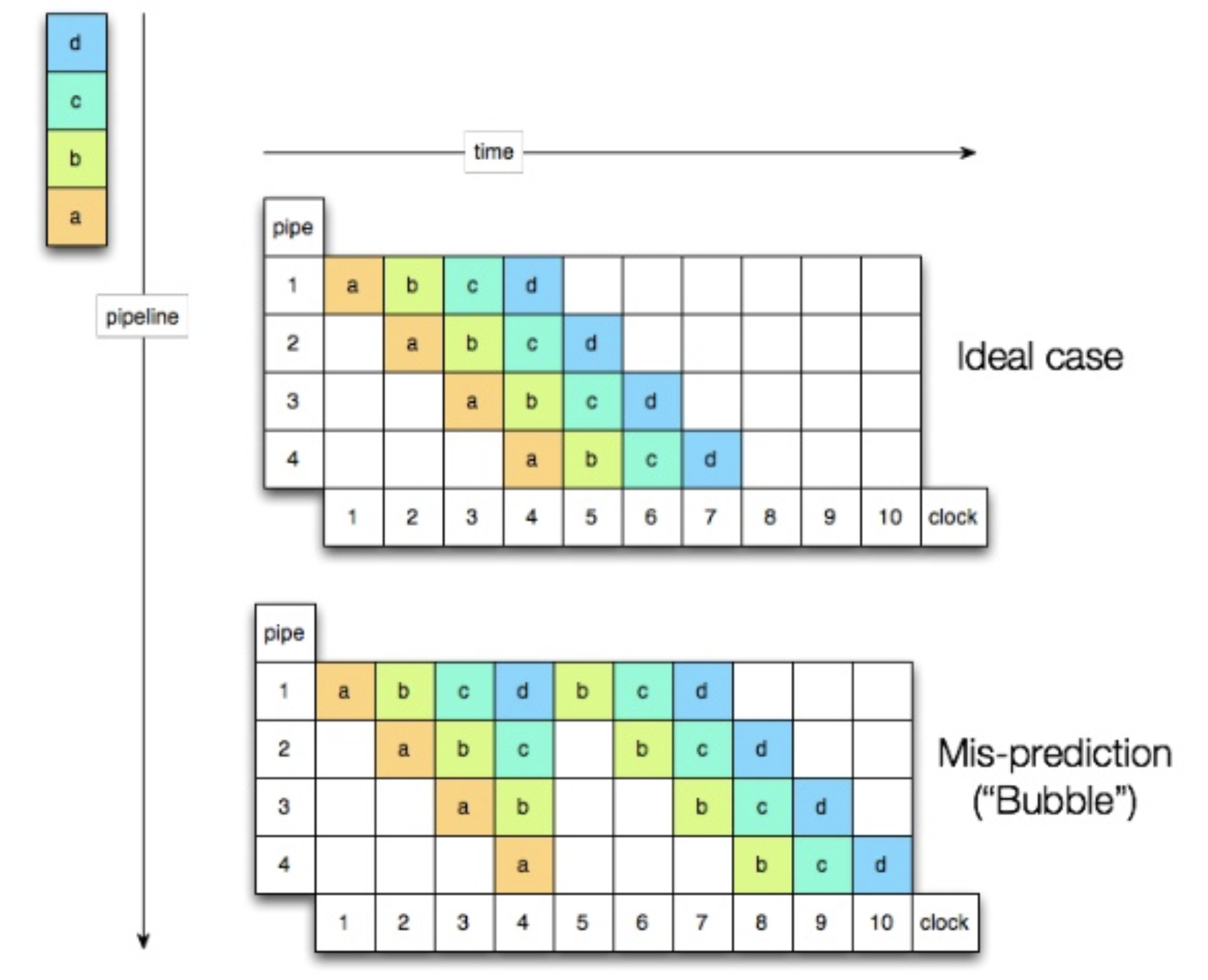
Definition Level을 if 문으로 체크할 경우 CPU Instruction pipeline에 Data dependent할 branch가 발생해 loop 수행 성능이 저하됨
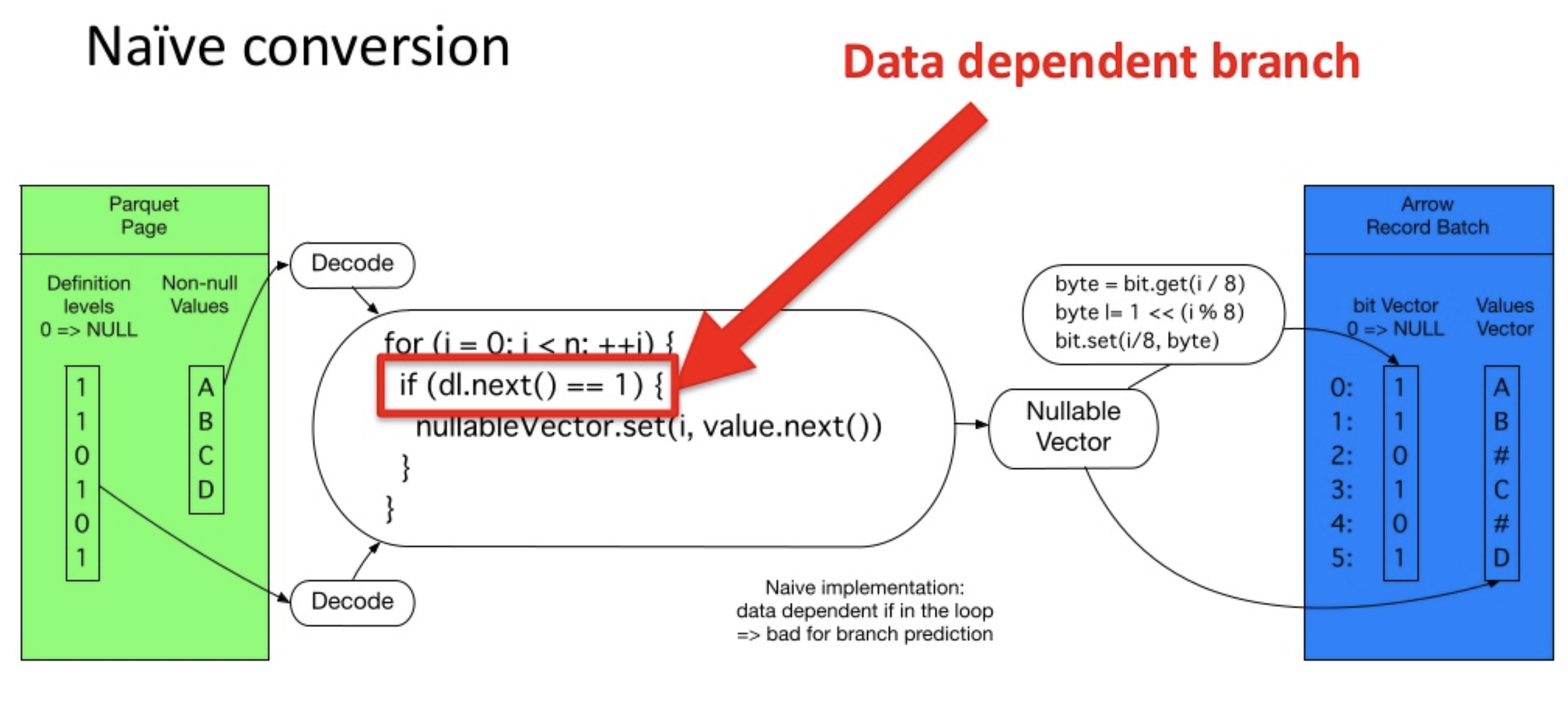
- CPU Pipeline
- CPU Instruction하나를 여러 step으로 나눠서 병렬 처리함
- Data에 dependent한 instruction(if문 같은 branch)은 해당 Data가 evaluation될 때까지 waiting하거나 값을 예측해서 미리 instruction실행
- 예측이 틀릴 시 이전 instruction으로 되돌아가 다시 실행 → Bubble
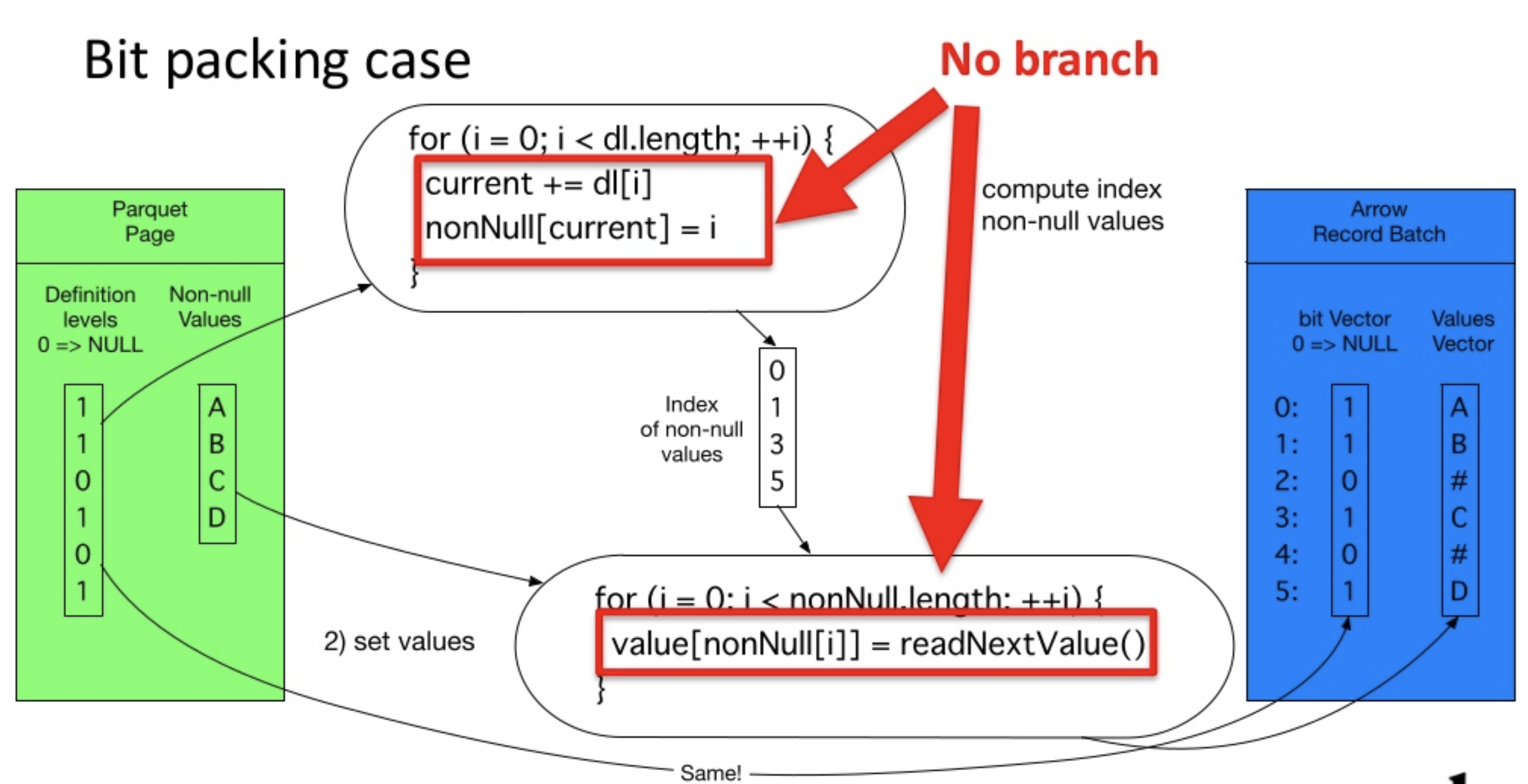
- Implementation without branch
Spark Integration (SPARK-13534)
- Arrow를 이용해 Pandas DataFrame과 Spark DataFrame의 Conversion Overhead를 줄인 패치
- PySpark 에서 toPandas 호출 → JVM Spark DataFrame의 collectAsArrow 호출 : 내부적으로 Spark Array[Row]를 Arrow File의 Payload로 전환해 Return함 → PySpark은 Arrow File의 Payload를 받아서 Python tuple형태로 Deserialize하지 않고 Pandas DataFrame으로 바로 전환
- JIRA : https://issues.apache.org/jira/browse/SPARK-13534
- PR : https://issues.apache.org/jira/browse/SPARK-13534
Reference
- Apache Arrow Columnar Format https://arrow.apache.org/docs/format/Columnar.html#
- Conversion between Arrow & Parquet https://youtu.be/dPb2ZXnt2_U https://www.slideshare.net/Hadoop_Summit/the-columnar-roadmap-apache-parquet-and-apache-arrow-102997214
- Apache Arrow github https://github.com/apache/arrow
- FlatBuffers Tutorial https://google.github.io/flatbuffers/flatbuffers_guide_tutorial.html