Spark 3.0 변경 사항
Language support
- Scala 2.12 , JDK 11, Python 2.x is deprecated.
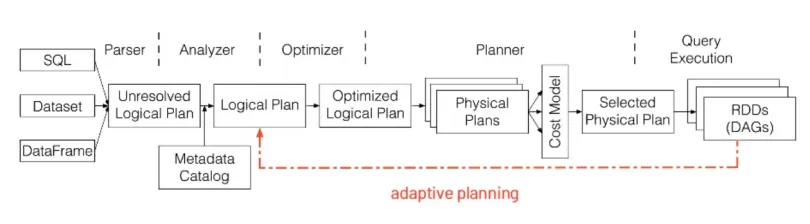
Adaptive execution of Spark SQL
- Spark 2.x Catalyst Optimizer : Rule + Cost based optimizer
- Table statics 기반 → missing, outdated
- Spark 3.x Catalyst Optimizer : Rule + Cost + Runtime ⇒ Adaptive Planning
- Task 수행을 마친 Stage의 결과의 statics를 바탕으로 아직 수행되지 않은 Stage들에 대해 Logical Plan부터 다시 Optimize
- Config
- spark.sql.adaptive.enabled → default false이고 true로 변경 시 enable됨
- 종류
- Dynamically coalescing shuffle partitions
- Shuffle 시 Partitioning에 대한 Runtime optimization
- 기존에는 Suffle partition 갯수가 spark.sql.shuffle.partitions config에 따라 결정되었음
- 너무 작을 때는 GC pressure 및 Spilling overhead발생
- 너무 클 때는 비효율적인 I/O 및 Scheduler pressure발생
-
개선 포인트 : 처음에는 Shuffle Partition갯수를 크게 잡은 후 Shuffling Stage수행 후 Data Size가 작은 Partition을 하나의 파티션으로 묶어서 Reduction Stage의 Partition수를 줄임
(ex) SELECT max(i)FROM tbl GROUP BY j
(1) 5개 partition으로 column j를 key로 shuffling을 수행
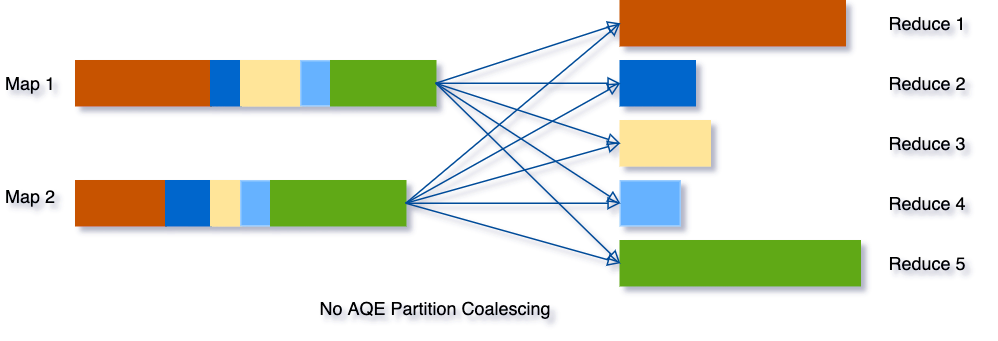
(2) Runtime Data size가 작은 파티션을 통합해 하나의 Partition으로 묶은 후 Reduction

- Dynamically switching join strategies
- 기존에는 Query planning 단계에서 ANALYZE Command로 table의 statics 정보를 얻을 수 있을 때만 Broadcast-hash join실행하고 statics 정보가 없을 때는 Sort-merge join을 실행했음 (Broadcast-hash join은 Local에서 join이 이루어지므로 shuffling이 발생하지 않아 Sort-merge join 보다 속도가 빠르다.)
-
개선 포인트 : Table에대한 Scan Stage가 끝난 후 Table 데이터 사이즈가 broadcast할 수 있을만큼 작다면 Sort-merge join에서 Broadcast-hash join으로 Plan을 변경함
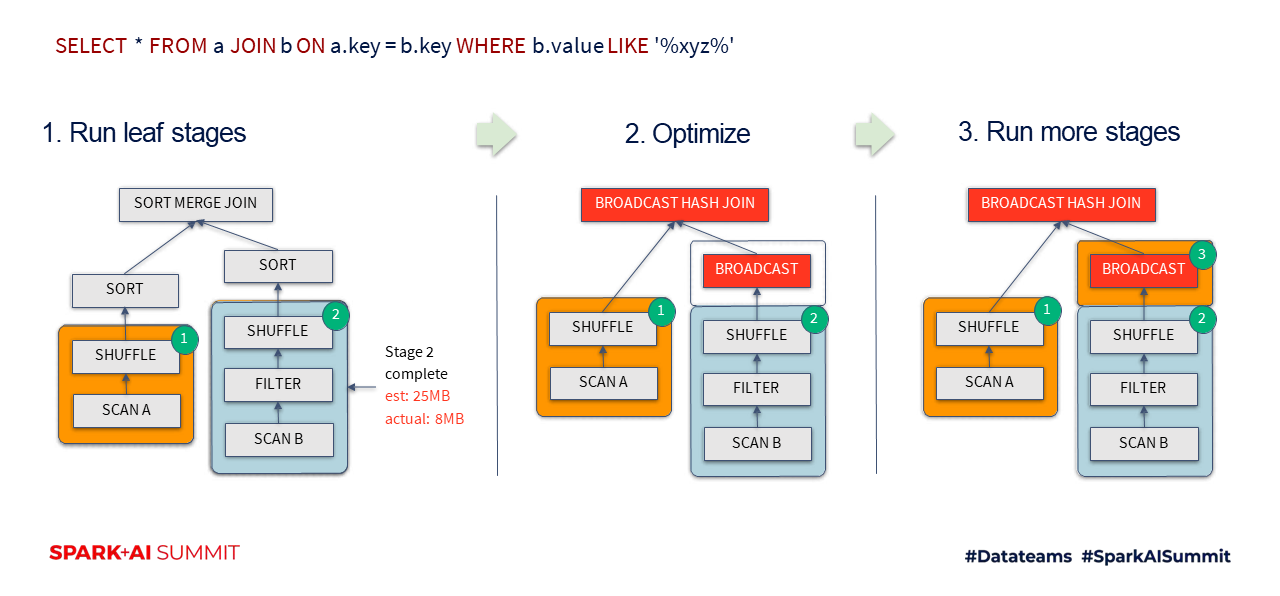
- Dynamically optimizing skew joins
- 개선 포인트 : Sort-merge Join 시 Skew된 Partition을 Runtime에 SubPartition으로 나눠서 Join
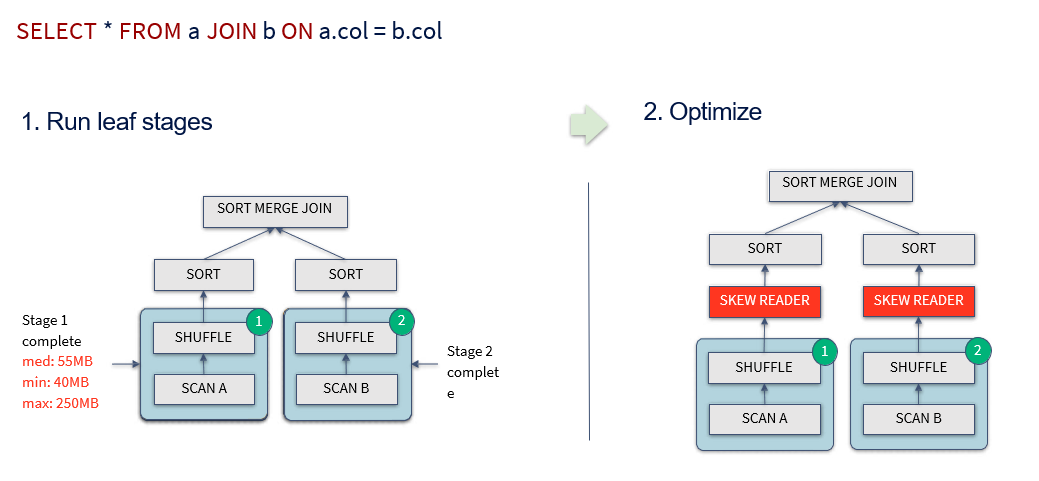
-
(ex) 두개의 Table A,B를 Sort-merge Join을 수행 시 Sort shuffling 시 Table A의 A0 Partition의 데이터가 너무 크다면 아래처럼 SubPartition으로 나눠서 Join
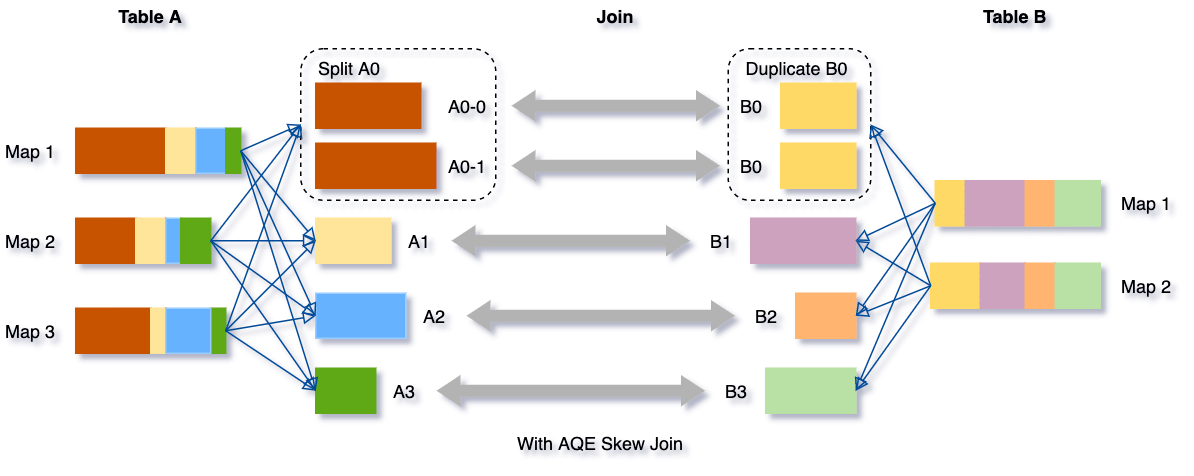
- Dynamically coalescing shuffle partitions
Dynamic Partition Pruning
- Spark summit slide
- Dimension table(사이즈가 작아서 Broadcast-hash join시 broadcast되는 table)과 사이즈가 큰 Fact table을 Join할 때 → Dimension table을 broadcast한 후 Fact table을 Scan하기 전에 Dimension table을 먼저 Scan한 후 이를 바탕으로 Fact table의 partition Pruning을 수행함
- TPC-DS 쿼리 102개 중 60개 Query가 2x ~ 18x까지 성능 향상
-
예시
Dimension Table t2과 Face Table와 t2를 Join
→ t2 & Filter Pushdown & Scan
→ Logical Plan변경 : Fact table t1에 t1.pKey.IN(SELECT t2.pKey FROM t2 WHERE t2.id < 2)라는 IN Filter 삽입
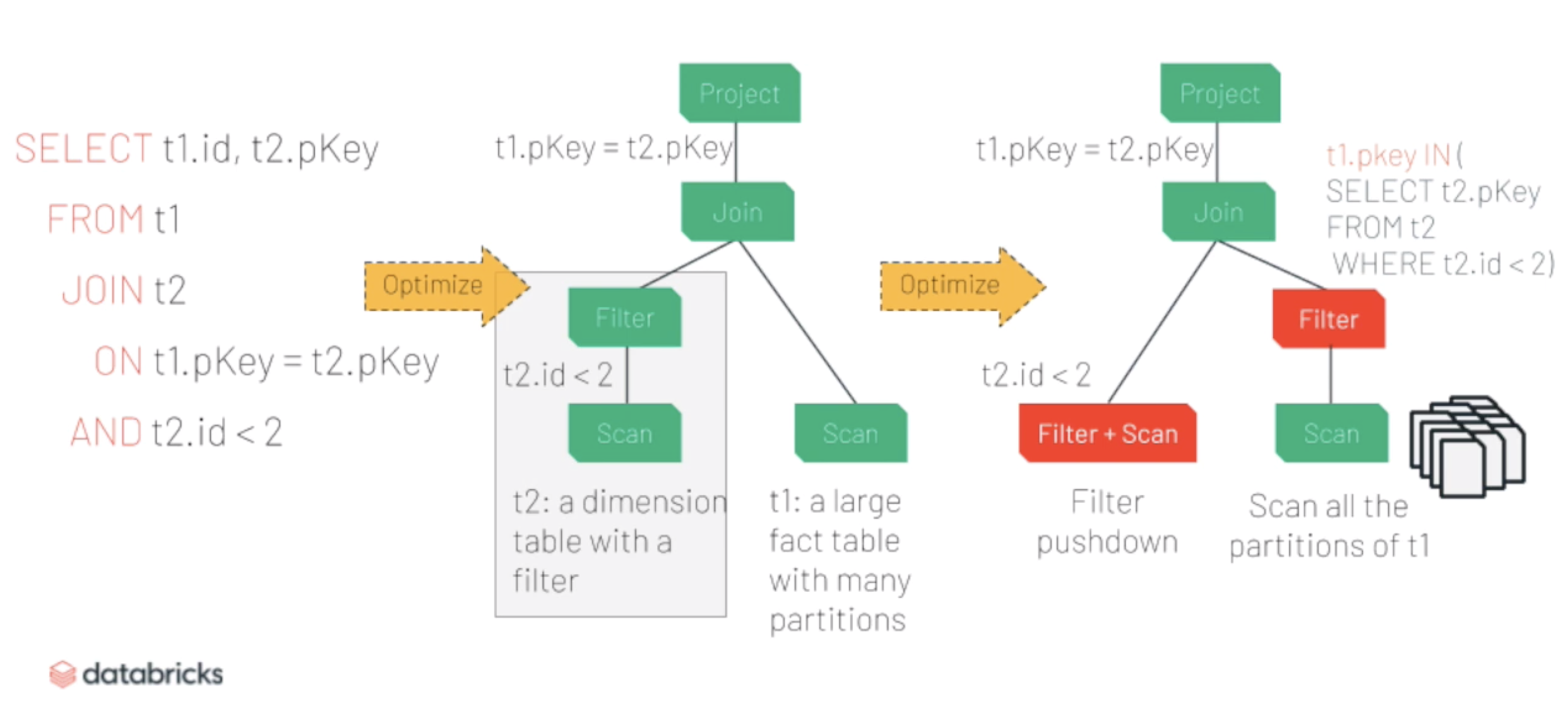
→ Runtime에 t2 table Scan을 마친 후 t1.pKey.IN(SELECT t2.pKey FROM t2 WHERE t2.id < 2)을 Evaluation하여 Value를 가진 IN Filter로 전환
→ IN Filter를 t1 table Scan으로 Pushdown후 Partition pruning 수행 (t1.pKey는 t1 table의 Partition column)
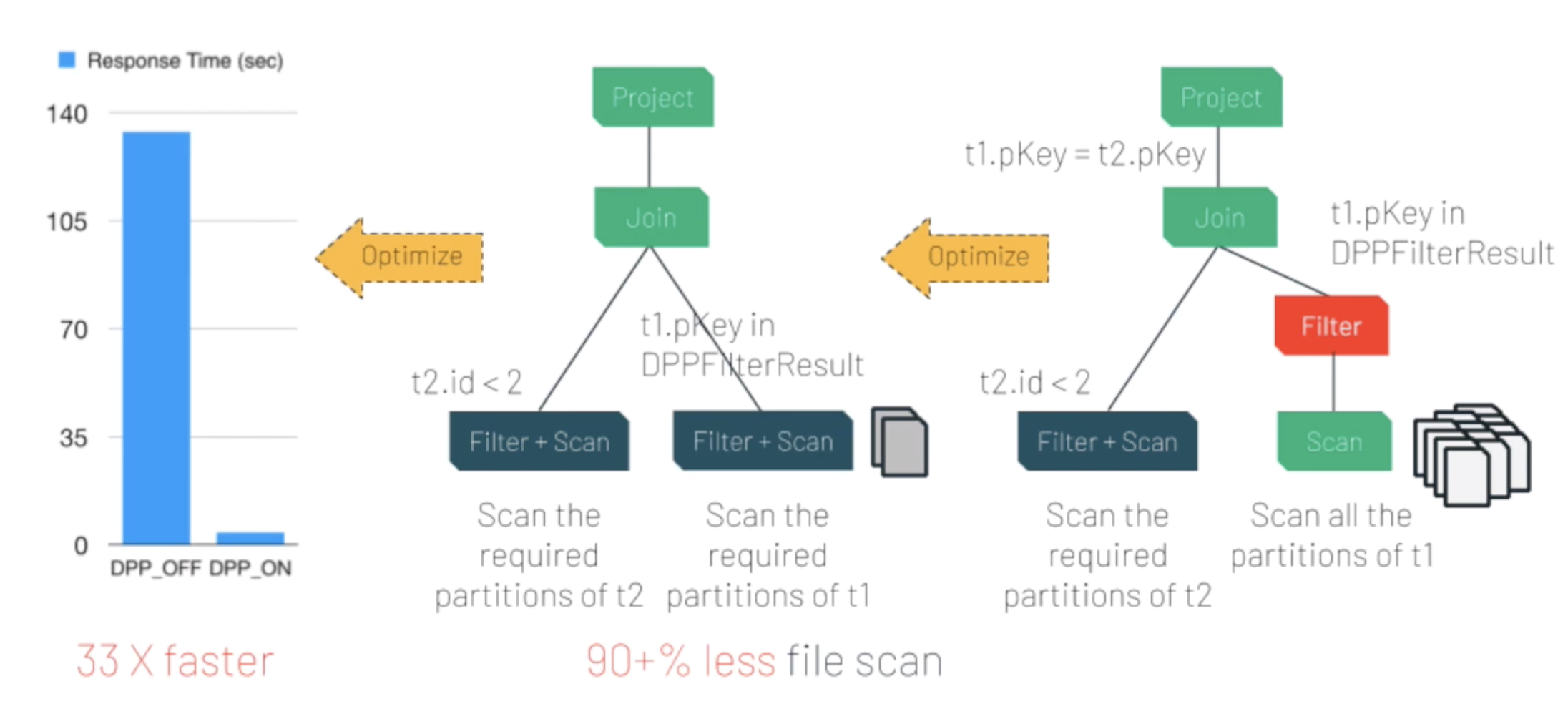
→ Partition pruning기반으로 Scan하는 파일 갯수를 줄여 성능 향상
Join Hint
-
How to use?
1 2 3 4 5 6 7 8 9 10 11
# Broadcast Hash Join: Fast(No shuffle, No sort), One side small table. SELECT /*+BROADCAST(a)*/id FROM a JOIN b ON a.key = b.key # Sort-Merge Join: Can handle any data size. shuffle + sort -> slow SELECT /*+MERGE(a,b)*/id FROM a JOIN b ON a.key = b.key # Shuffle Hash Join: Shuffle but no Sort. OOM if data are skewed. SELECT /*+SHUFFLE_HASH(a,b)*/id FROM a JOIN b ON a.key = b.key # Shuffle Nested Loop Join: Does not require JOIN key SELECT /*+SHUFFLE_REPLICATE_NL(a,b)*/id FROM a JOIN b
Pandas UDF & Python Type Hints
New Functions
-
Mediums : Spark 3.0 — New Functions in a Nutshell
1 2 3 4 5 6
sinh,cosh,tanh,asinh,acosh,atanh,any,bit_and,bit_or,bit_count,bit_xor, bool_and,bool_or,count_if,date_part,extract,forall,from_csv, make_date,make_interval,make_timestamp,map_entries map_filter,map_zip_with,max_by,min_by,schema_of_csv,to_csv transform_keys,transform_values,typeof,version xxhash64
Accelerator Aware Scheduling
- Standalone, YARN, k8s에서 Accelerator Resource Scheduling 지원
- 현재는 GPU만 지원하지만 앞으로는 FPGA나 TPU도 지원 예정
- 현재는 Application Level에서만 resource 사용량을 Cluster Manager에 요청할 수 있음. 앞으로는 Job, Stage, Task Level로 지원 예정
- Discover & Request Accelerator
- SPARK-27024: Driver/Executor가 accelerator resource 인식하는 script 설정 가능
- spark.driver.resource.${resourceName}.discoveryScript
- spark.executor.resource.${resourceName}.discoveryScript
- SPARK-27366: Application Level로 Accelerator Resource 설정
- spark.executor.resource.${resourceName}.amount
- spark.driver.resource.${resourceName}.amount
- spark.task.resource.${resourceName}.amount
-
Task Context 에서 Task 수행 중에 할당된 Accelerator resource를 얻어와 Task 수행 시 사용할 수 있음
1 2 3 4 5
assigned_gpu = TaskContext.get().resources().get("gpu") .get.addresses.head with tf.device(assigned_gpu): # training code
- SPARK-27024: Driver/Executor가 accelerator resource 인식하는 script 설정 가능
Monitoring and Debuggability
- New Spark Streaming UI
- New EXPLAIN Command
1 2 3 4
df.explain("simple") == df.explain() df.explain("extended") == df.explain(true) df.explain("cost") # Cost Base & obtain statistics df.explain("formatted")
Built-in DataSources 개선
- CSV Filter pushdown : SPARK-30323
- Parquet/ORC Nested column 성능 개선
- Parquet filter pushdown for nested columns : SPARK-17636
- Parquet/ORC Column pruning for nested columns : SPARK-25603
- Binary file data source : Spark 3.0 Read Binary File into DataFrame
Catalog Plugin API
- Table Metadata관련 Plugin API가 추가되었음
- DataSource Level에서 table catalog API를 지원할 수 있게 됨 : DataSource가 V2 API 지원 시 meta-store역할도 담당할 수 있을 걸로 보임
- Proposal Document : Spark API for Table Metadata → SPARK-31121
- SQL Conf 로 Catalog Plugin class 설정 : spark.sql.catalog.catalog-name=com.example.YourCatalogClass
- Plugin의 Property도 함께 설정 가능 : spark.sql.catalog.catalog-name.(key)=(value)
- API Doc : CatalogPlugin , TableCatalog
- Proposal Document : Identifiers for multi-catalog support → SPARK-27066
DataSource V2 API
- When to use DataSource V2 API?
- Data Source에서 Catalog 기능 지원하고자 할 때
- Data Source가 batch & streaming을 동시에 지원하고자 할 때
- Scan 성능 향상 시키고자 할 때 → Vectorized reader 지원 + shuffle시 partition pruning 기능 지원(Dynamic partition pruning 기능을 의미하는 듯?)
- DataFrameWriter에서 Task & Job 단위 transaction(commit/abort) 지원
Spark AI Summit 2018 : Apache Spark Data Source V2SlideShare: (→ 이 Link에서 사용한 DataSourceV2 class 등은 2.4 API이고 3.0에서는 삭제되었다.)
- Example
JDBC DataSource with V2(→ 이 Link에서 사용한 DataSourceV2 class 등은 2.4 API이고 3.0에서는 삭제되었다.)- Madhukar’s Blog : datasource-v2-spark-three (→ 3.0 기준으로 작성된 blog)
Accelerating Query with GPU
- Spark 자체가 GPU를 이용한 Query 가속을 지원하는 것은 아님
- Spark 3.0부터 Driver/Executor를 위한 Plugin API를 제공(SPARK-29397)
- 별도의 Project인 Spark-rapids를 Plugin으로서 import한 후 GPU로 Query 실행을 가속할 수 있다.
- Spark-rapids : Rapids Accelerator for Apache Spark
- GitHub : https://github.com/nvidia/spark-rapids
- Catalyst Optimizer의 Physical Plan 을 GPU용으로 전환
- Scan : Row Iterator기반 RDD → ColumnBatch 기반 RDD
- Operation : row-by-row기반 Operation(Filter, Shuffle, Join, Aggregation등) Plan (CPU) → ColumnBatch기반 Operation으로 바꾼 후 GPU에서 수행
- RAPIDS Plugin for Apache Spark Developer Overview
- Spark AI summit 2020 : Deep Dive into GPU Support in Apache Spark 3.x